ML Lecture 2 Machine Learning Fundamentals
传统编程 vs ML 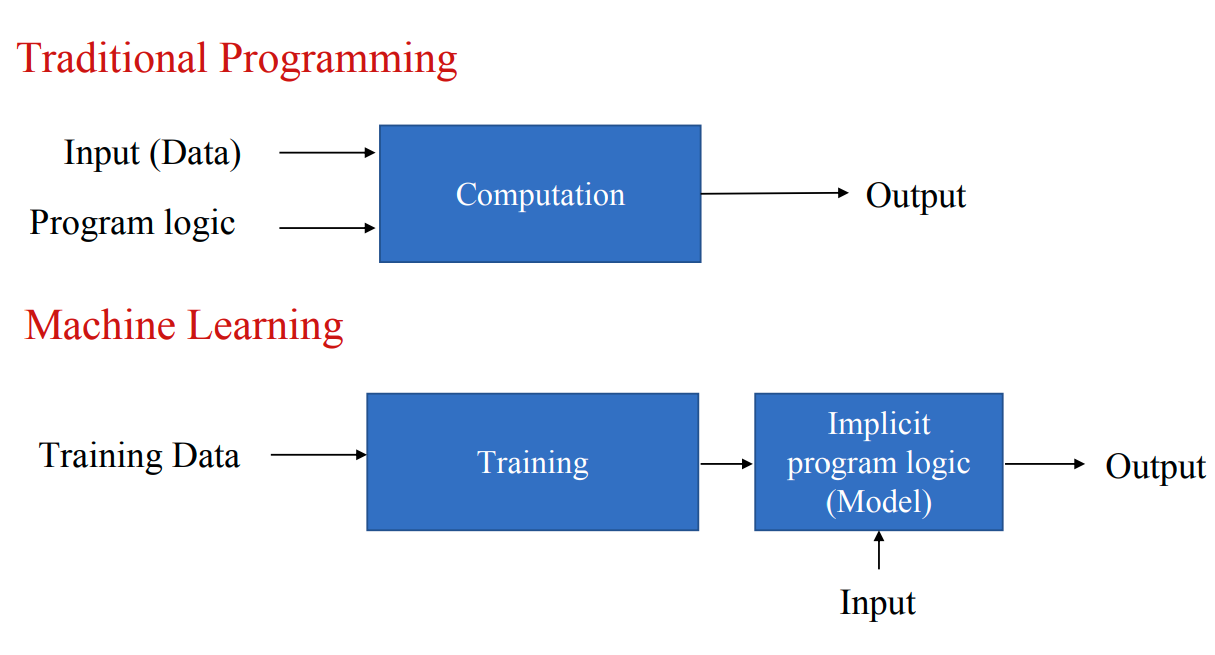
ML 中的基础概念
数据集 Dataset
代表一组数据的集合。 一个数据集能被表示为
训练集被用于训练ML模型。
训练集的大小通常大于测试集,通常为总数据的60%。
测试集被用于评估 (Benchmark) 一个被训练后的模型。
测试集独立于训练集。
测试集通常为总数据量的20% - 25%。
模型 Model
- 使用某些ML算法从数据中学习出的表示 被训练后的模型可以用来推理/预测一些没有出现过的数据。
样本 Sample (实例 Instance)
- 代表数据集中的一个元素 对于数据集
是数据集中的第n个样本。
一个水果数据集中的第n个样本可能是一种水果的图片和名称。 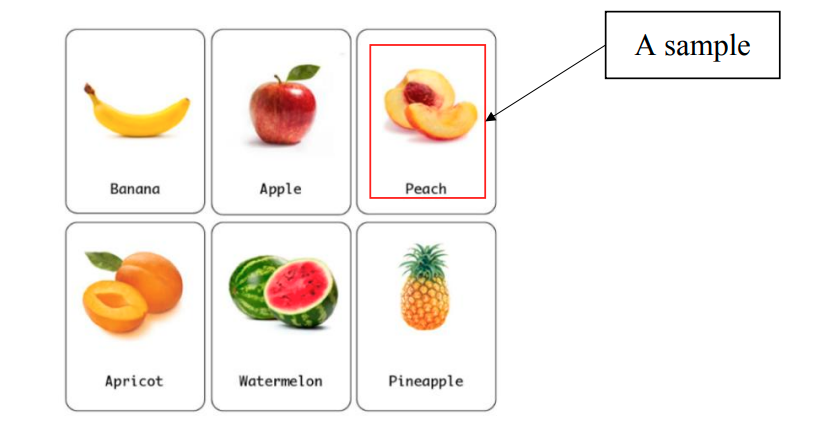
特征 Feature
- 特征是数据的一种可度量的属性。
一组特征可以方便地用一个特征向量 Feature Vector来表示。 特征向量会作为 输入 Input 被送入模型。
为了对水果进行分类,特征向量可以写成
这些特征对每一个样本都适用。
标签 Label
标签是模型需要预测的那个值。 在水果的例子中,标签就是水果的名字,比如 apple、orange、banana 等。
监督学习中的基本概念
监督学习 Supervised Learning
模型在一个带标签的数据集 Labelled Dataset上进行训练。
带标签的数据集 Labelled Dataset
同时包含输入和输出(标签)参数的数据集。
水果分类示例:
- 数据集:
- 第n个样本:
是水果的特征, 是图片的标签。
训练与测试 Training & Testing
Training(训练):
- 训练是这样一个过程:将训练数据输入给机器学习算法,使其从中学习。
- 训练完成后,我们得到一个训练好的模型,可以把新的输入映射到输出。
Testing(测试):
- 测试是一个用测试数据集来评估已训练模型性能的过程。
分类 classification
Classification(分类):是一种监督学习任务,其中输出是离散的 Discrete。
分类任务示例:水果分类、人脸识别、网络流量异常检测等。 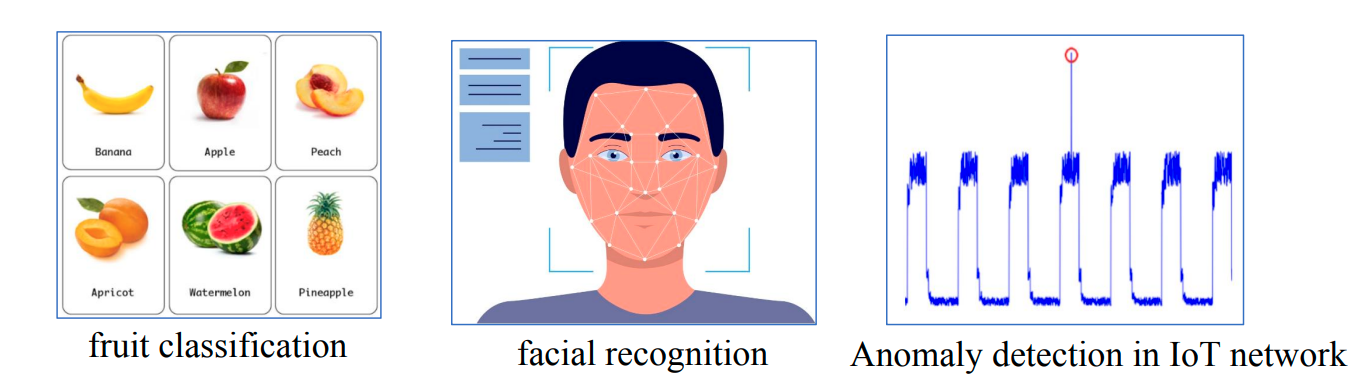
回归 Regression
Regression (回归):是一种监督学习任务,其中输出是连续的 Continuous。
回归任务示例:金融预测、交通事故预测等。 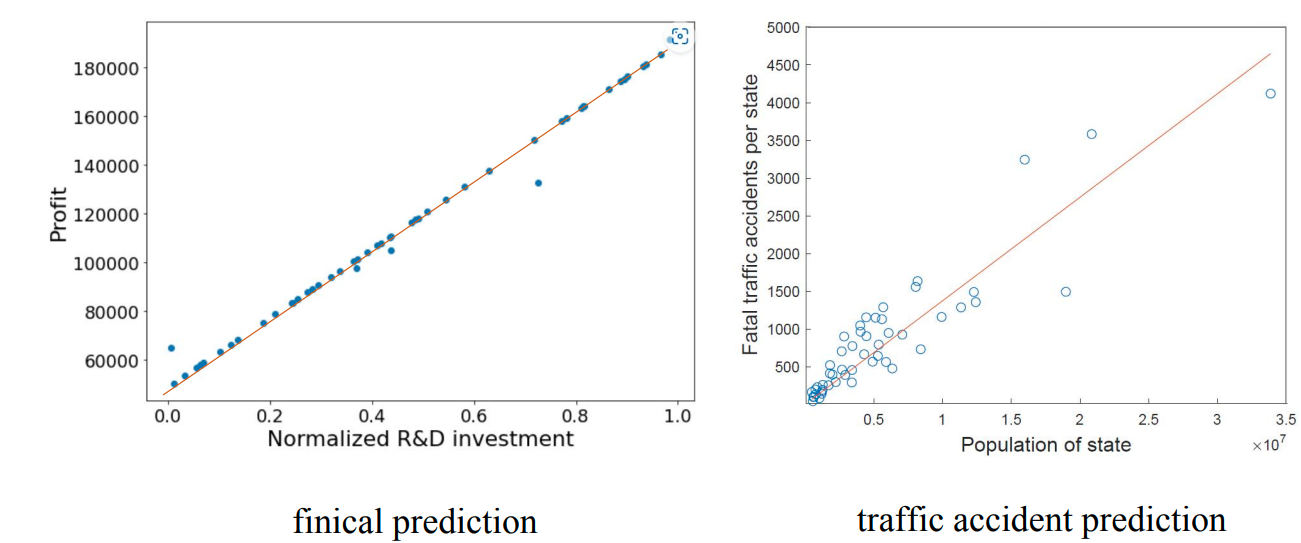
半监督学习 Semi-supervised Learning
在半监督学习中,模型是用如下数据集来训练:
- 一小部分带标签的数据;
- 大量无标签的数据。
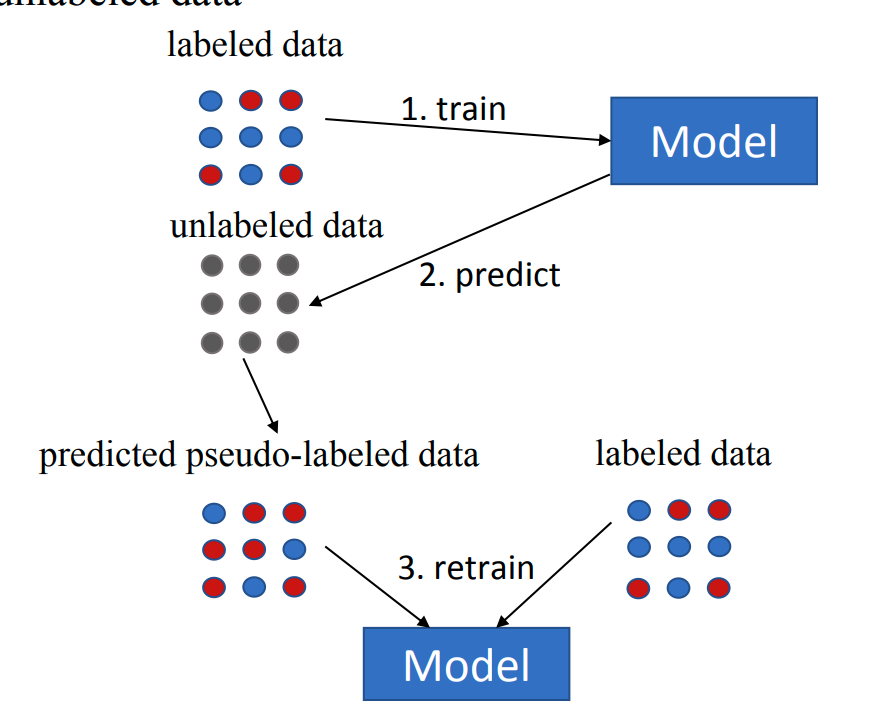
无监督学习 Unsupervised Learning
- 无监督学习的目标是对数据的底层结构或分布进行建模。
- 无监督学习模型的输入全部是无标签数据。
由于没有标签,无监督学习相较于监督学习更具挑战性。
把输入映射到输出:数据表示 Mapping Inputs to Outputs: Data Representation
ML 流程 ML Procedure
开发阶段 Development
- Represent data: 需要把数据翻译成机器学习算法能理解的“语言” → 数据编码(Data encoding)
- Select ML algorithms: 选择机器学习算法,用参数模型/非参数模型。
- Evaluate output: 评估输出结果的预测误差。

应用阶段 Application

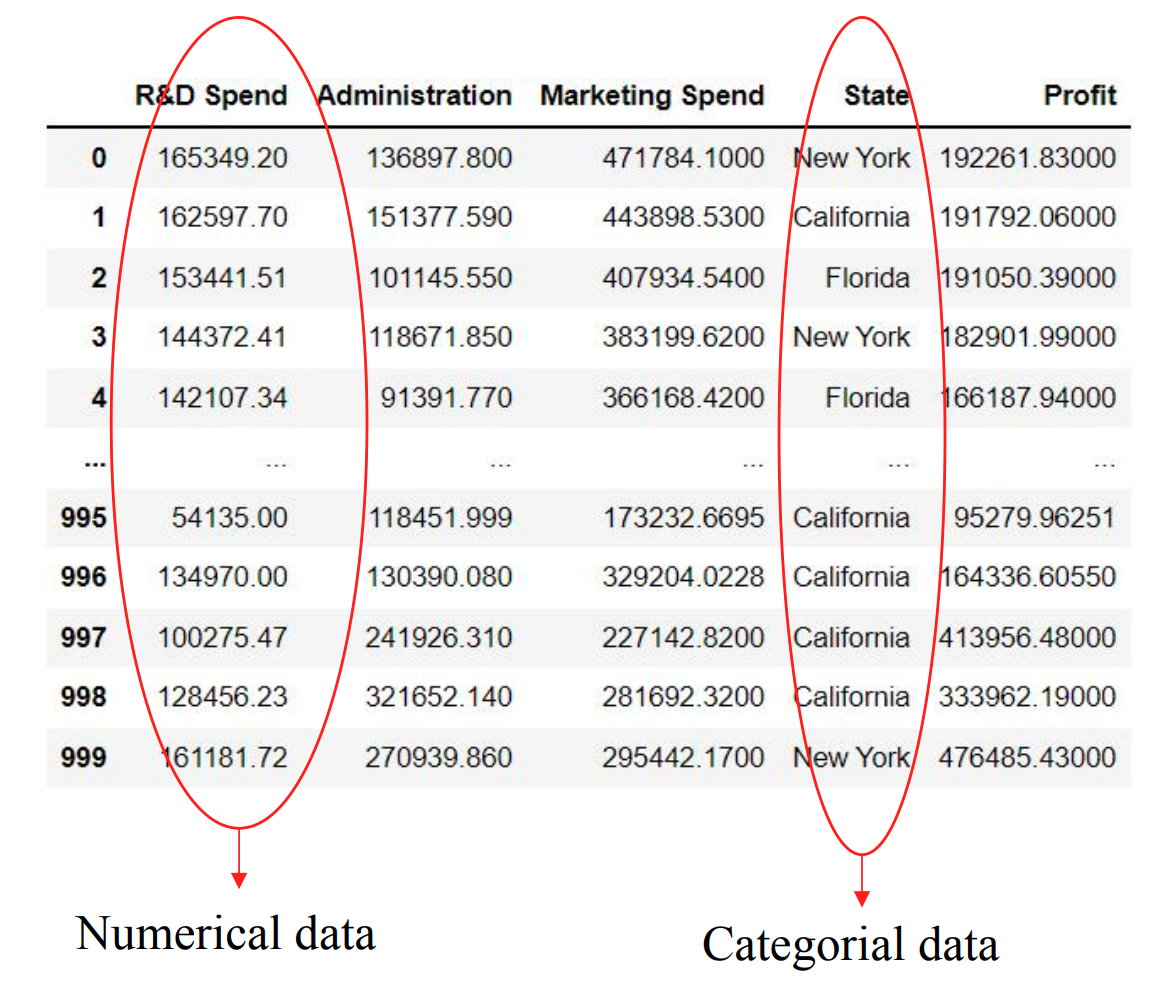
数据类型 Data Types
数值数据 Numerical Data
- 用数字表示的数据;
- 可以做算术运算(+、−、×、÷)。
数值数据的类型
离散数据(Discrete data):
有可数、固定元素的数据,通常用整数表示。
例:年龄(25 岁、89 岁)、学生人数(30 人、40 人)。连续数据(Continuous data):
在某个区间内可以取任意值的数据。
例:身高(177.4 cm)、速度(18.44 m/s)。
分类型数据 Categorical Data
- 按组 / 类别存储;
- 用名字或标签来表示。
类别数据的类型
- 二元数据(Binary data): 真 / 假,通常编码成 0、1。
- 名义数据(Nominal data): 也叫命名数据,例如性别(male, female),人名(Julia, Jack, …)。
- 有序数据(Ordinal data): 元素之间有顺序或带有评分等级。
- 例如餐厅菜品评分:strongly dislike, dislike, neutral, like, strongly like。
有序数据的编码 Encoding of ordinal data
有序编码 Ordinal encoding
- 每一种不同的有序取值分配一个整数值;
- 通常从 0 开始编号。 例:
- strongly dislike → 0
- dislike → 1
- neutral → 2
- like → 3
- strongly like → 4
名义数据的编码:独热编码 Encoding of nominal data – One hot encoding
一个数据点
- 如果
属于第 类,则 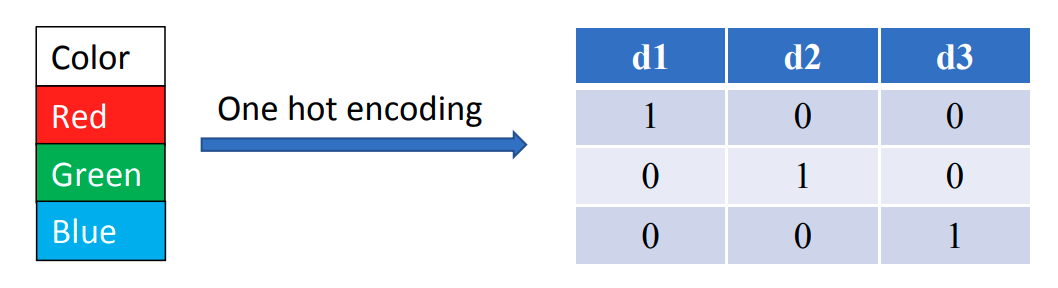
名义数据的编码:哑变量编码 Encoding of nominal data – Dummy encoding
Dummy Encoding 使用 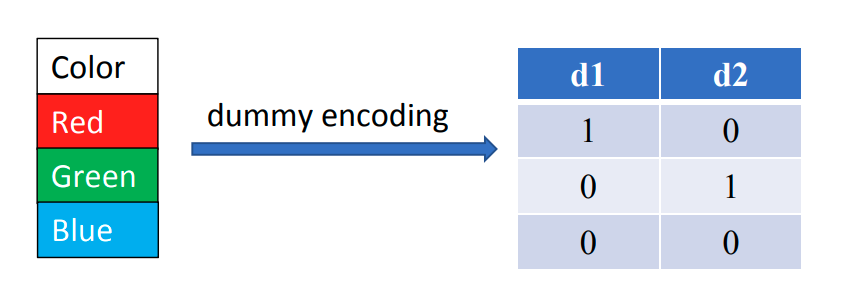
(其实就是使不使用全0向量的区别())
把输入映射到输出:参数化机器学习 Mapping Inputs to Outputs: Parametric ML
参数化模型 Parametric Model
- 参数化模型把模型简化为一种已知形式的函数(例如一条直线),用来刻画输入和输出之间的关系。
- 典型例子:线性回归、逻辑回归、简单神经网络等。
优点:
- 简单(Simple): 容易理解,也便于解释结果。
- 快速(Fast): 从数据中学习的速度快。
- 数据需求少(Less Data): 通常只需要较小的数据集。 缺点:
- 受限(Constrained): 严格受限于预先设定的函数形式。
- 复杂度有限(Limited Complexity): 更适合较简单的问题。
- 可能拟合不好(Maybe Poor Fit): 有时难以很好地逼近真实的映射关系。
参数化模型:线性回归 Linear Regression
线性回归通过下面的线性函数来学习两组变量
:待预测的因变量 Dependent Variable; :用来预测 的自变量; - 这种关系由系数
和常数项 体现,它们在训练过程中被学习得到。
线性回归把一个或多个数值型输入映射到一个数值型输出。
线性回归的优点
- 对因变量与自变量之间近似线性关系 Linear relationship的数据表现良好;
- 实现简单,易于理解和解释,训练效率高。 线性回归的缺点
- 只有在“因变量与自变量之间是线性关系”这一假设成立时才有效;
- 对 离群点(outliers) 比较敏感。
把输入映射到输出:非参数化机器学习 Mapping Inputs to Outputs: Non-parametric ML
非参数化模型 Non-parametric Model
- 非参数化模型不会对模型的形式做很强的假设。
- 它直接从数据本身中学习。 例:支持向量机(SVM)、k 近邻(KNN)等。
优点:
- 灵活性(Flexibility): 能够拟合大量不同形式的函数。
- 高性能(High performance): 可能得到性能更高的模型。 缺点:
- 通常需要更多数据和更长的训练时间。
KNN
KNN 是一种监督学习方法,可用于分类和回归问题。 KNN 的特点:
- 惰性学习(Lazy learning): KNN 没有独立的训练阶段,在分类时直接使用全部数据。
- 非参数化: 不假设任何具体的映射函数形式。
KNN 在分类中的应用:
手写识别、人脸识别、文本分类等。
KNN 的步骤 Procedures of KNN
- Step 1: 选择
的取值。 - Step 2: 计算查询样本与每一个训练样本之间的距离(或相似度)。
- Step 3: 按照与查询样本的距离从小到大对训练样本排序,选出距离最近的
个邻居。 - Step 4: 根据这
个邻居中出现次数最多的类别,把该类别作为查询样本的类别。
示例
- 假设训练数据有两个类别:A 类和 B 类。
- 现在有一个新的数据点
,任务是判断 属于哪一类。 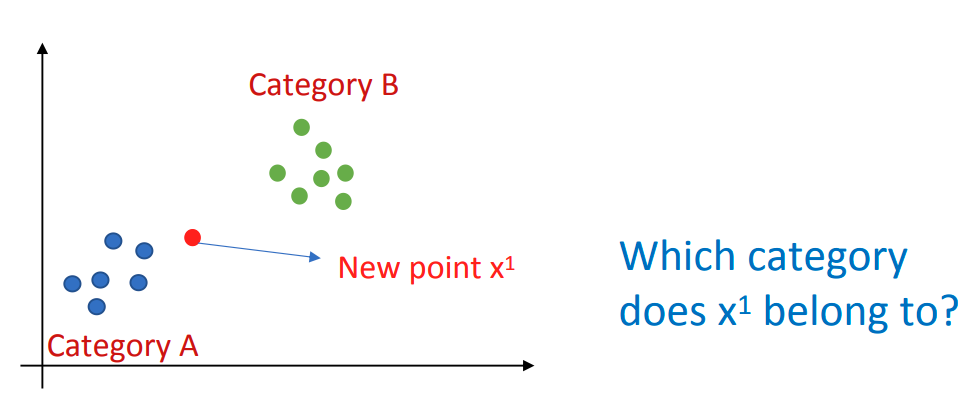
Step 1: 选择
在这个例子中,我们取
Step 2: 计算查询点与各个训练点的距离。
- 欧氏距离(Euclidean Distance)是常用的距离度量。
- 两点
。 Step 3: 找到点 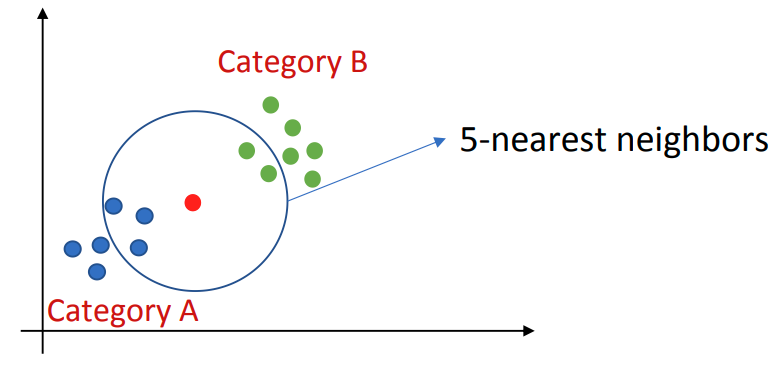 由于这 5 个最近邻中大多数属于 A 类,因此
由于这 5 个最近邻中大多数属于 A 类,因此
K 的选择T he selection of
- 选择一个最优的
的过程叫做超参数调节(hyperparameter tuning)。 - 实际上有一些经验法则可以帮助选择
。
选择
不宜太小,也不宜太大。 - 当
太小时:噪声对结果的影响会更大。 - 当
太大时:模型可能学得不够好(过于平滑)。
- 当
通常选为奇数(避免分类时平票)。 - Domain Knowledge在选择最优
时也很重要。 - 平方根经验法(Square Root Method):
将设为训练集中样本数的平方根。
把输入映射到输出:评估输出 Mapping Inputs to Outputs: Evaluate Output
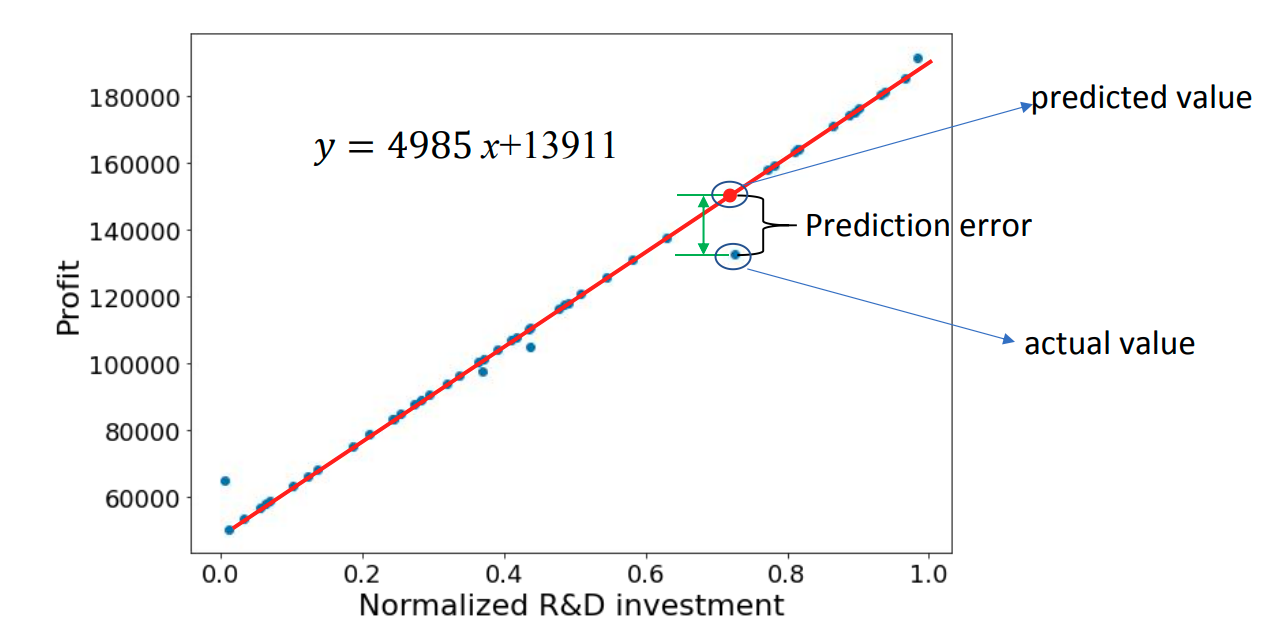
预测与预测误差
- Evaluate output: 评估输出 → 预测误差 Prediction errors。

预测任务 Task of prediction:
用模型去预测新的输入数据的结果。
一个预测器(模型)的性能,用它的预测误差(prediction error)来衡量。
预测误差 Prediction error:
模型给出的预测值与真实值之间的差。